关于电子书整理这个问题其实我念叨了好久,一直也没个明确的好办法,所以也就一直没有实施。今天这篇主要是做个记录,具体效果要等我用一段时间看看。- 扫描版电子书很多,还有一些其他格式的电子书都混在一起
- 肯定不能手动挑,也不想把网盘文件全下载下来以后再整理
周末了正好跟豆老师聊一下,也算是理了理思路,经过来来回回的补充和修改,最后出了一版Calibre + Umi-OCR的方案。【Calibre + Umi-OCR 自动分流组合】
 逻辑:
逻辑:
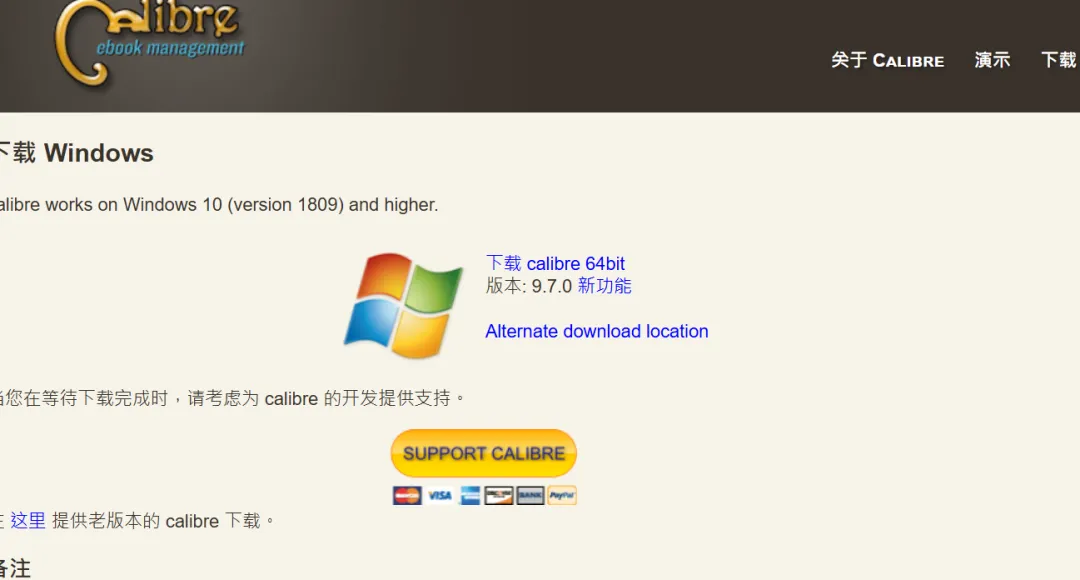
Calibre 自动过滤处理:EPUB、MOBI、纯文本可复制 PDF(不走 OCR,秒解析)
下载地址:https://calibre-ebook.com/download_windows
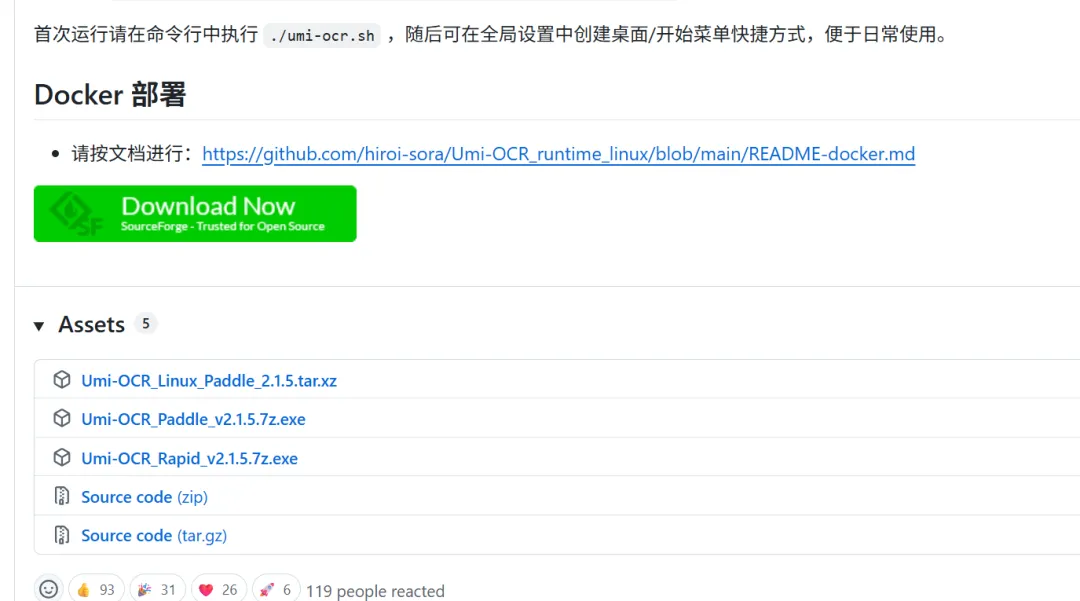
剩余无法复制、纯图片扫描 PDF / 漫画图集 → 扔进 Umi-OCR 批量 OCR
下载地址:https://github.com/hiroi-sora/Umi-OCR/releases
支持网盘、移动硬盘、外接 U 盘、NAS、共享文件夹,不用把文件复制到电脑本地、不占 C 盘空间,直接原地整理解析
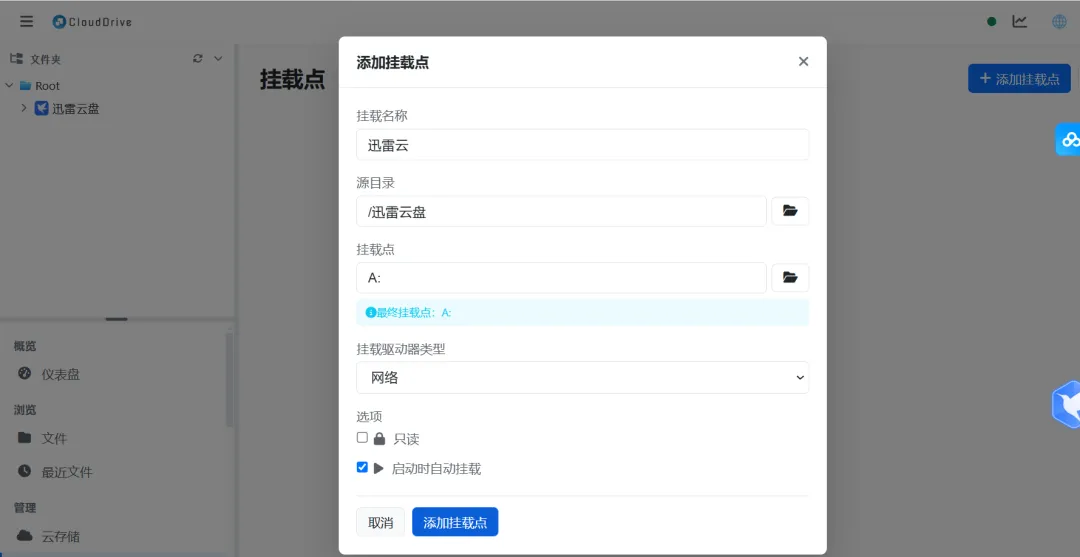
百度网盘好像只有文件夹同步,选这个会触发自动下载的,不能用这个添加书籍,但是平时用来整理其他资料还是可以的。CloudDrive免费版的话可以挂一个虚拟盘,默认不下载完整文件,只缓存少量。下载地址:
https://github.com/cloud-fs/cloud-fs.github.io/releases/tag/v1.0.6
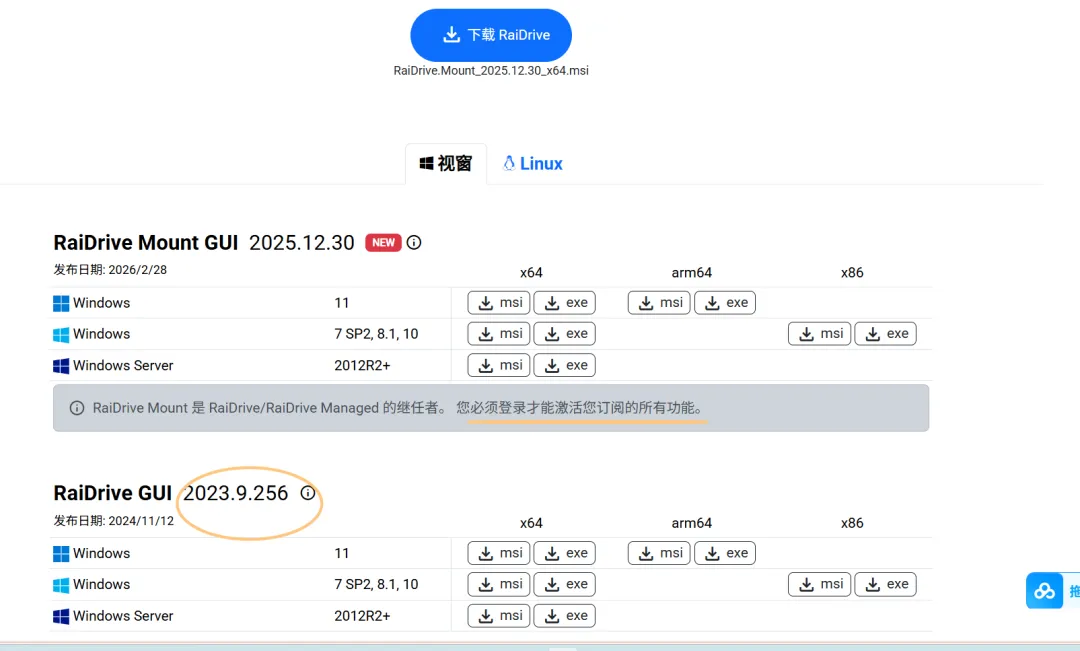
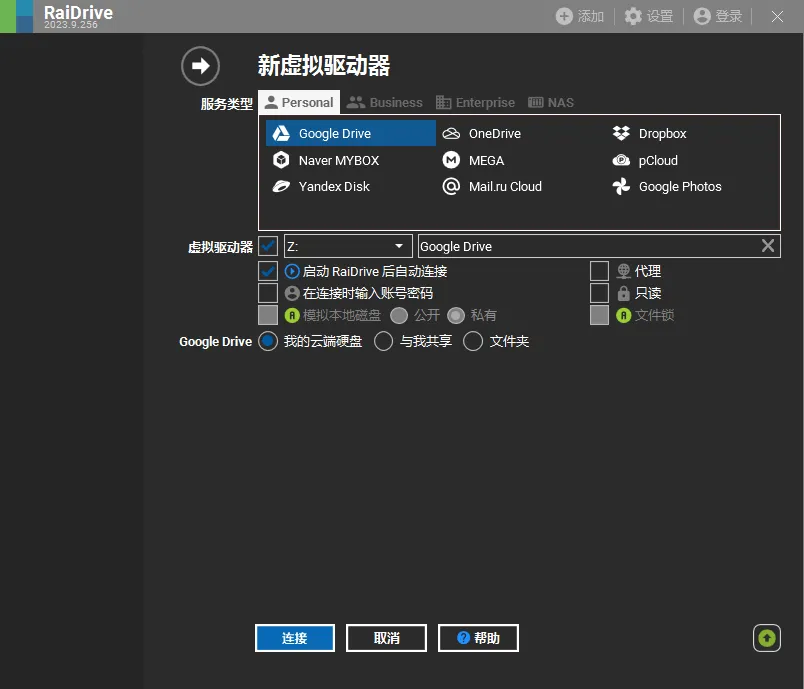
我本来挂了迅雷,因为只能挂载一个盘,就又换成阿里云了。RaiDrive可以挂多几个,选旧的版本,最新那个版本要登录才能用。不过旧版就没有国内的盘,OneDrive和Google是都支持的下载地址:https://www.raidrive.com/zh-hans/download最后要再设置一下缓存
磁盘缓存位置 D:\CloudDrive_Cache 放在 D 盘,不占 C 盘空间
磁盘缓存大小限制 2048 MB 最多只缓存 2GB,用完自动清理
🚀 完整闭环操作步骤
第一步:用 Calibre 自动分流电子书
- 能正常读取文本的 普通电子书(EPUB、MOBI、带文本层的 PDF)会直接入库
- 无法读取文本的 扫描版 PDF / 图片书 会被自动识别出来,可以在列表里筛选这些文件,导出到一个专门的「待 OCR 文件夹」里
第二步:用 Umi-OCR 批量处理扫描书
- 把 Calibre 里导出的「待 OCR 文件夹」(或者直接网盘里的扫描书文件夹)拖到左侧的处理区域
- 保存文件类型:
layered.pdf 双层可搜索文档/txt标准文档
- 点击「开始任务」,软件会自动跳过带文本的 PDF,只处理扫描版文件,直接生成可搜索的双层 PDF和,保存回网盘目录里
第三步:把处理好的电子书重新导入 Calibre
- 回到 Calibre,点击「添加书籍」,选择 Umi-OCR 处理好的「解析后的电子书」文件夹
- 导入后,这些扫描书现在也能被 Calibre 正常读取文本、搜索、管理了
- 这时候可以给所有电子书统一整理元数据、分类、打标签,做成一个干净的个人书库
第四步:闭环完成,后续使用
- 以后在网盘里新增电子书,只需要重复「导入 Calibre → 筛选扫描书 → Umi-OCR 处理 → 重新入库」的流程
- 所有文件都存在网盘里,不占本地空间,Calibre 里的书库也可以同步到其他设备
- 要先拿少量文件测试:第一次处理可以先少放几本电子书试试,确认流程没问题再批量导入,避免出错
这样一套流程跑下来,就实现了「网盘存文件 + Calibre 管库 + Umi-OCR 处理扫描书」的闭环,以后整理电子书就不用手动下载分类再去OCR 了。
 完整流水线
完整流水线
看起来还是挺像那么回事儿的,具体效果还等我用用看来着。

 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
