电子书整理2
- 2026-07-11 03:50:50
电子书整理2换了个据说比WinRAR更快一点的解压软件,因为当年下电子书的时候好多打包来的压缩文件,还得先解压了才能后续处理。 一直在用WinRAR,我还以为这个是Windows自带的呢,某天用的时候发现它居然会跳广告,今天问了豆包,才知道原来不是Windows自带的。 豆包推荐了7-Zip、NanaZip、PeaZip、Bandizip 6.x 旧版,我去官网下载了7-zip和Bandizip,蛮刁钻的还,免费版有广告的,一下火起换了个别的下载网站的链接,下载了稍微旧一点的版本,倒是也不影响使用。
电子书的话昨天下载的umi-ocr用了一天,转换以后的pdf成品还是蛮不错的,txt的差了点,我觉得这样就算转成md效果也不会好的。速度也慢了点,我有点没耐心,而且只能转纯文字,也不能直接生成md格式,虽然豆包说txt直接改成md大小和精度都没什么变化的,但我就是感觉这样中间还要转一手好麻烦。 今天换成超能模式继续跟豆老师聊,其实我应该是要尽量把电子书都转成md格式,才能以后喂给本地ai模型组成知识库,实现我想要的那种精读然后可以问ai问题的模式。 那就是个好浩大的工程- -还没开始我就有点累了,但还是坚强的开始了! 所以今天是电子书整理方案2: 之前已经在obsidian装了ai插件和ollama本地模型,可以看这篇 最简本地 AI+Obsidian
先要装转md文件的应用 因为我有很多扫描电子书里面是带图片的,甚至有些干脆就是杂志那种排版比较复杂的,所以必须是可以ocr图片的,豆包推荐了MinerU和Maker,MinerU也是同一个问题,最新版已经加载了ai,并且我下载了以后根本找不到添加文件夹的按钮,受不了,想在github下载旧版本的吧又突然连不上了,又换成命令行版的。 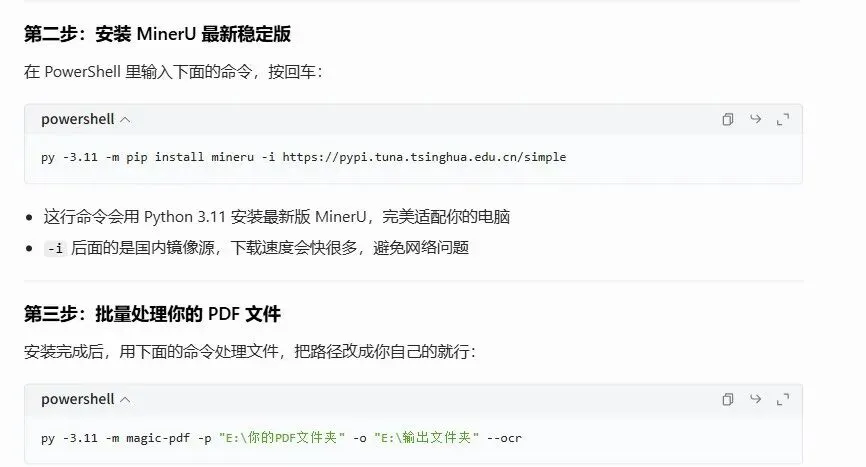
注: 如果电子书文件是存在百度网盘之类的挂载的虚拟盘,那转格式的时候必须保持网盘客户端运行:处理过程中不能关闭客户端,否则会断开连接,导致读取失败。 漫画和视频可以做索引md放进obsidian 到这里一切都挺好,但是嘛,运行批处理的时候就不行了,问豆包呢,说是mineru不行,又让我换个扫描pdf的,换成了tesseract 在开了加速器也时不时断联的github上下载了tesseract 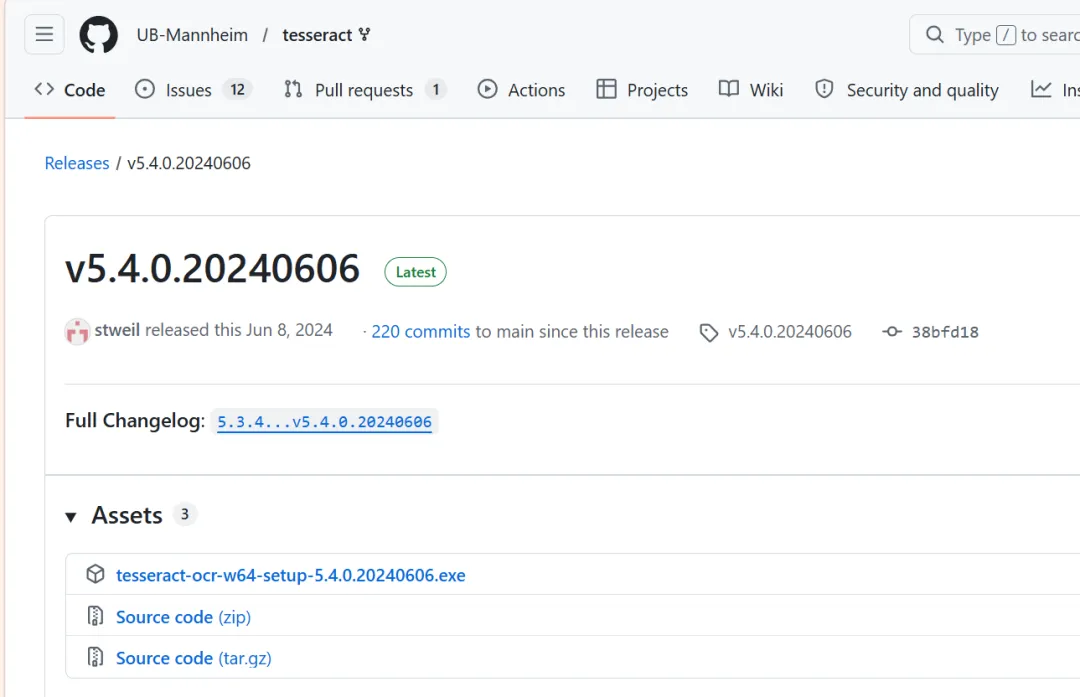
然后苦苦一通安装调试,结果批处理老是窗口玩消失,改来改去发现豆包把我的用户名写错了,又改还是不行,最后存了py文件换成在cmd运行了…… 
虽然但是赚了十来本,等我拖到obsidian里面一看几乎全军覆没,只有一个word的成品没啥问题,所以命令行也失败了。 好,又回到开头了,到处找mineru的旧版本,GitHub上是源码的,还要加载环境什么的才能用,很复杂的样子,豆包劝我算了,要好十几个G的空间??还要吓唬我说就算装好了后续也会有很多问题,难绷- = 
给我个下载链接但是失效的,啊!好无语! 最后总算在夸克网盘里搜到了下载 
默默等待下载完成中……tbc 
总之流水线目前就是: 后面边用边改吧
原料电子书:随便散在网盘、移动硬盘各种盘,不用管
电子书转成MD文件
转好的 MD文件:统一保存在本地一个文件夹
Obsidian 读这一个文件夹,就是完整知识库
第一步, 安装 Python 3.10
去官网下载 Python 3.10 安装包,新版本的话MinerU不支持。
文件夹路径里不要有中文、空格和特殊符号,避免识别失败。
输出文件夹可以提前新建好,软件会自动在里面生成和原文件结构一致的目录。
我让豆包按照我的文件路径写了个一键批处理,还可以加上处理完成后关机、每次打开弹出选择文件夹的窗口之类的细节要求,让豆包不断完善。
原文件 → 转 MD → 入库 Obsidian → AI 自动打标签 → AI 问答 / 整理 / 沉淀
本文来自网友投稿或网络内容,如有侵犯您的权益请联系我们删除,联系邮箱:wyl860211@qq.com 。
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 【电子书】 | 21本济群法师著作《人生佛教》系列PDF文件资源链接
- 【编号6034】【亚马逊原版---电子书合集】【免费分享】
- 电子书《图解足球实战技术 假动作70招》
- 更新 | 市场监管法规读本(电子书)V3.1.7下载
- 电子书 剑桥雅思语法精讲精练+剑桥雅思核心词汇精讲精练(基础篇+高级篇)资料齐全,发三本PDF,送音频
- WorkBuddy实战:为网友下载506页的在线电子书
- 电子书分享合集-4.26
- 电子书 丽声北极星自然拼读全6级|音频+课件+教案,4-12岁英语启蒙神器!【资源全】72套绘本+拼读体系+配套资源,一套搞定自然拼读!
- 2025知产典型案例|网售盗版电子书著作权侵权案(2026)
- 百度网盘资源:收集整理一波电子书资源,手快有手慢无链接自取
