TransLit:AI 翻译电子书之我见
- 2026-07-13 13:13:46

TransLit 是我“歪波”(Vibe)出最为“实用”的一款工具。越是实用,越是常用,越容易发现问题,工具也就越发“锋利”。当前版本令到我满意,可以一写,相当于在船身刻上一道印记。
问题出现我再——

之所以用 Google AI Studio 写一个新的翻译工具,而不用现成的“沉浸式翻译”、AiNiee[1] 或者 LinguaGacha[2],主因是我用惯的 Gemini 不再提供足量 API。
但 Google AI Studio 的原生网页应用,却可以相对充足地调用 Gemini 3.0 Flash 模型。
我之前的版本答案(详见 Vol.010 在你手心上写的字),是复制一页 HTML 原文,粘贴到 AI 窗口,然后翻译出 Markdown 格式译文。为了解放人力,我决定简单“歪波”一个 AI 翻译工作台:需要人工处理的部分放在最前面让用户设置,可以机械执行的部分用程序解决,剩下的纯粹翻译任务交给大模型。
于是,我有了第一个版本(详见 Vol.015 个人的体验),可以把 EPUB 内容拆分成 Markdown 片段,然后分片递给 AI 翻译,合并后套用内置的 CSS 样式,导出为固定格式的 EPUB。
这里需要说明一点,我不认为翻译后要保持原有 EPUB 排版,因为首字下沉之类的西文样式实在不太适合汉字。
初版基本可用,但还是遇到一些小问题,比如说中文 Markdown 的渲染问题。该问题 Obsidian 也有,简单说就是,星号与标点的位置决定了加粗、倾斜等样式能否正常渲染。
在 Obsidian 里,我会把句号、逗号等标点固定放在星号标记的外部。但因为 AI 的表达惯性,你只好在提示词中限定,但就像英美式引号的问题,积习难改。
我最后用了另一种方法(同样写在提示词里):
遇到需要加粗或斜体文本,请使用 HTML 标签 <b>加粗</b> 和 <i>斜体</i>,绝对不要使用 Markdown 的星号(* 或 **)类似于这样的小问题,还有浏览器缓存(关闭窗口、关机后,下次可以继续翻译)、添加第三方接口配置(能用 API 接其他大模型)等等,但我只是给 AI 描述一番,之后问题就解决了,并不了解实现细节,就不在文中赘述了。
重新发现“术语表”

在用 AiNiee 之类工具的时候,需要你自行配置“术语表”,之前我还写过让 AI 提取术语表的提示词。
但我后来放弃了,心想如果遇到人名不翻译,保留原文,大概就不会出现前后不一致的问题,不需要我专门“跑一趟”了。
直到近期翻译一本日文小说,我才发现这条指令执行得并不好。若能完整保留日文中人名的汉字,效果应当不错,但翻译时却会冒出“罗马字”。
提示词针对英译中这一特定场景,我猜想这可能是症结所在。于是,我添加了源语言选项,可以改变提示词中的相应内容(内容源自李继刚的英译中提示词,其实我在读思果的《翻译研究》和《翻译新究》,核心观点也是“翻译是重写”,或许我可以用更多书中原话重写一版“重写式翻译提示词”),比如:
【遗忘之律】忘记[SOURCE_LANG]的句法。忘记[SOURCE_LANG]的语序。只记住它要说的事。当然是不可行的。
译完仍有罗马字,可谓“条条大路通罗马”。
我只好重新发现“术语表”这个东西。
Google AI Studio 给了 Flash 模型充足的用量,但调用速率还是有限,所以哪怕作了分片,也还是串行翻译。我只好安慰自己,译得再慢,也比你读得快。
在这漫长的接龙里,我想,前一位译员完全可以把翻译时发现的新“术语”附在翻译结果后面,传递给下一位,这样就实现了“一遍翻译”。
其他应用是先跑一遍(可能用小一些的模型),记录下全部术语表,之后带着整本书的术语表,并行翻译每一段。但我的调用速率有限,还希望尽可能减少术语表长度,所以想出了这种经济适用型策略。
多任务处理确实是考验模型,但经过测试,Gemini 3.0 Flash 可以实现这个工作流。为了尽可能精简术语表,我还打了几个“补丁”:
一是在每个分片添加新条目后,搜索“未翻译文本”,如果没有出现该词,就不要加入术语表。
二是在每翻译十个分片之后,调用大模型判断有无不适合加入术语表的词汇。比如,有些术语的译法固定,前后文中几乎不可能有差别。
以下是当前版本的术语表相关提示词,在写术语表的提示词里,我避免用“术语”这个词,这是我有意为之的。
export const TRANSLATION_PROMPT_GLOSSARY = `【对齐系统】1. **核心原则**:【宁缺毋滥】。 - 仅提取“虚构专有实体”(虚构人名/地名、特殊设定自造词)。 - **严禁包含** - 译法固定的**专业术语** - **常规多义词** - **现实世界已存在**的实体/地名/人名。2. **过滤机制**: - 提取前请自问:“这是一个只在这本小说里才有的特殊名词吗?”如果答案是“否”或“不确定”,**直接放弃提取**。 - 提取前必须对比已知表格,如果已经存在,**直接忽略,不要重复输出**。3. **格式**:\`SOURCE: {原文} | TARGET: {译文}\`,仅在 <glossary> 标签内列出本段**新发现**且未在已知表中出现的上述高风险/专有条目。4. **一致性**:参考当前表格,确保全文核心译名与特殊词意绝对统一。5. **返回格式约束**:<translation>[Markdown 内容]</translation><glossary>SOURCE: [原文1] | TARGET:[译文1]</glossary>`;export const GLOSSARY_OPTIMIZER_PROMPT = `你是一位专业的“术语表审查专家”。你的任务是清理并精简当前的术语表,使其更具参考价值并降低后续翻译成本。【严禁包含】1. **常识性词汇**:已有标准翻译的客观事物(如:啤酒杯、电击枪、手机)、无他译法的专业术语。2. **汉字重合词**:日中翻译中,汉字意义完全一致且无须转换的词。3. **冗余词条**:意思重复或过于碎片的词条。【执行任务】1. **降噪**:彻底删除所有不符合“必须包含”原则的词条。2. **去重与合并**:如果同一原文有多个译名,选择最符合文学语境或最专业的一个。3. **格式化**:每行一个词条,严格遵循 \`SOURCE: {原文} | TARGET: {译文}\`。输出规范:- 仅输出清理后的术语列表。- 严禁输出任何解释、开场白、Markdown 围栏(\`\`\`)或总结。- 如果没有任何有效术语,请保持输出为空。`;当前版本使用方法

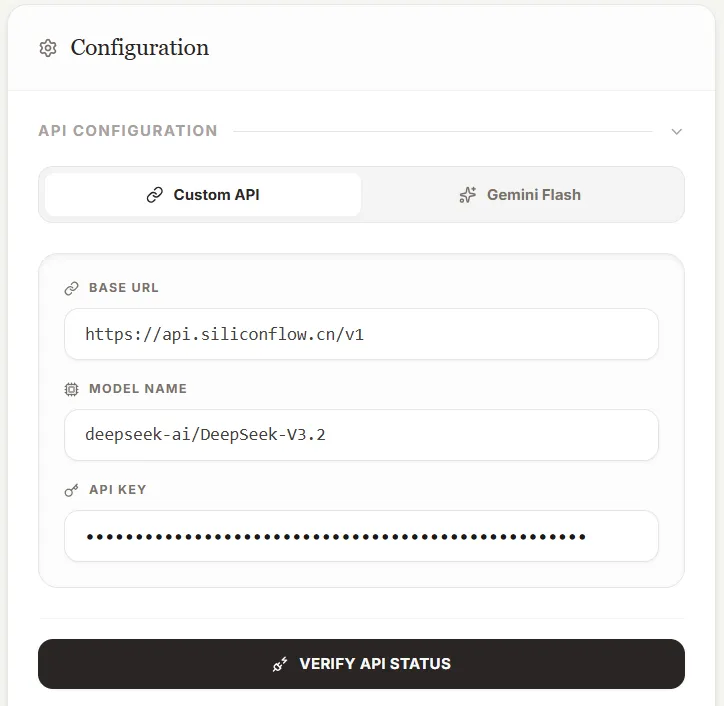
Google AI Studio 访问链接:TransLit[3]。
可以配置第三方的 API,填好之后,点击下方“Verify API Status”,检查连接是否成功。
当然,最好直接用 Gemini 3.0 Flash 模型,毕竟是我做这个应用的初衷。
如果非要使用第三方 API 的话,不妨在 GitHub - TransLit 2.0[4] 下载后本地运行:
解压后在项目目录中打开命令行 运行 npm install 运行 npm run dev(以后只需运行这句即可)
之后是翻译相关的设置:
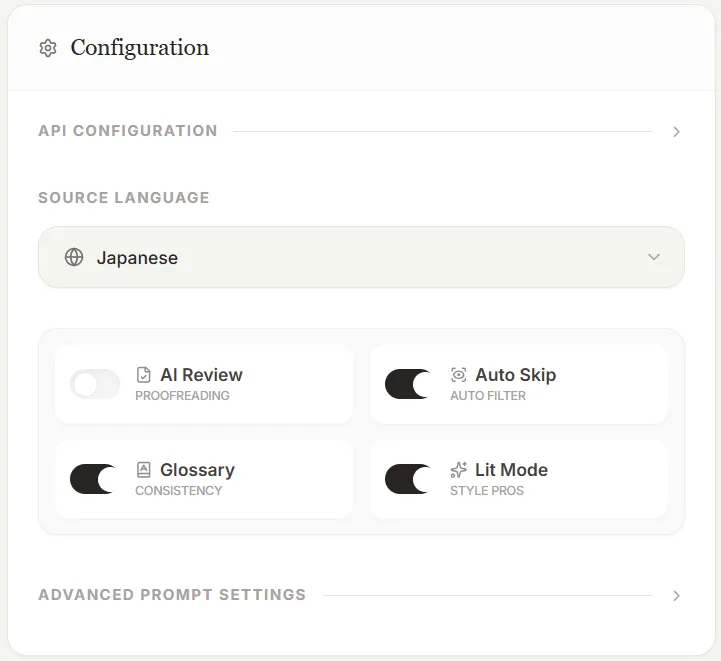
选择源语言。当然,不选也可以翻译,但前面提到过,源语言与翻译提示词有联动,我还是强迫自己选一下。 - AI Review
是 AI 校对,也就是翻译完再校对一遍。Gemini 3.0 模型不太会出现掺杂其他语言单词的情况,所以我一般不选这一项,基本没用过。 - Auto Skip
是事先跳过一些目录、参考文献等不值得翻译的页面。这部分是匹配实现的,所以不算准,还是需要在 Chapter 页面手动选择; - Glossary
是术语表系统。根据经验,叙述类作品需要选择此项,非叙述类可不选。 - Lit Mode
是使用保存在后台的翻译提示词。不选此项,可在下方填写自定义提示词。
把 EPUB 电子书拖入框中,即可进行翻译。
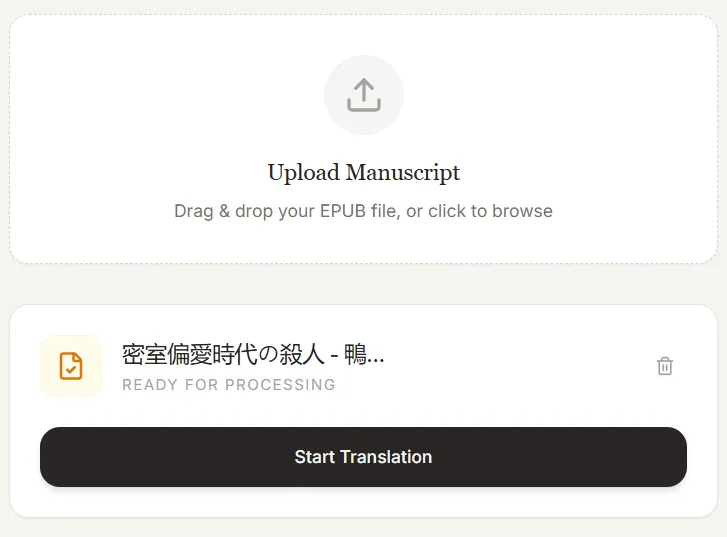
界面右侧,可以看到三个选项卡——
先去CHAPTER 页面手动处理一下 EPUB 页面(并非小说的“章”):

图中四个按钮分别是“预览”(方便用户判断)、“不译”(不翻译但保留原文)、“删除”(不翻译而且直接删除)和“重译”(一般是流程结束后,翻译不成功时使用)。
CONSOLE 页面用来展示翻译进度:
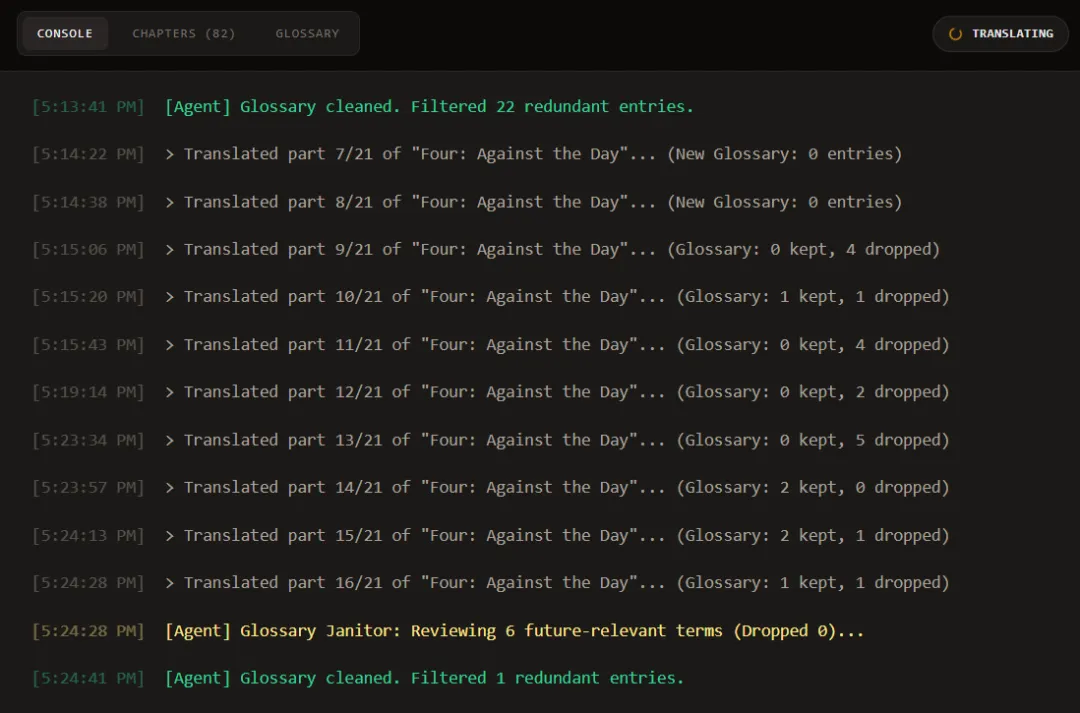
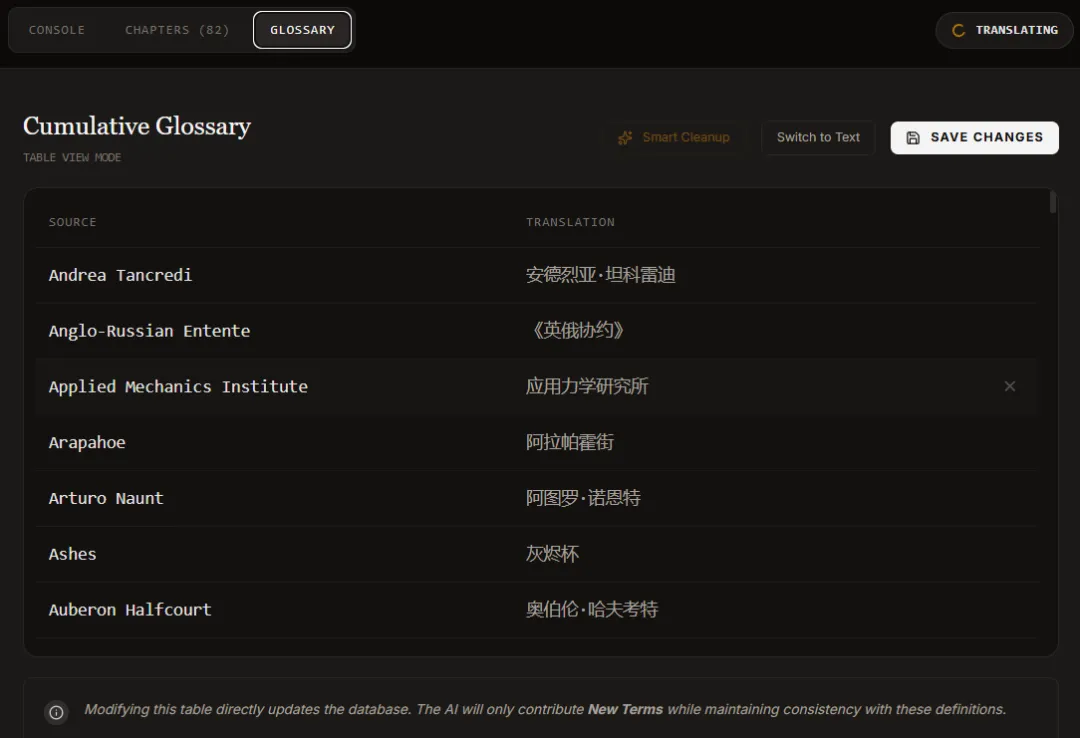
GLOSSARY 页面用来记录当前术语表,可以自行编辑(增删改),注意修改后及时保存。
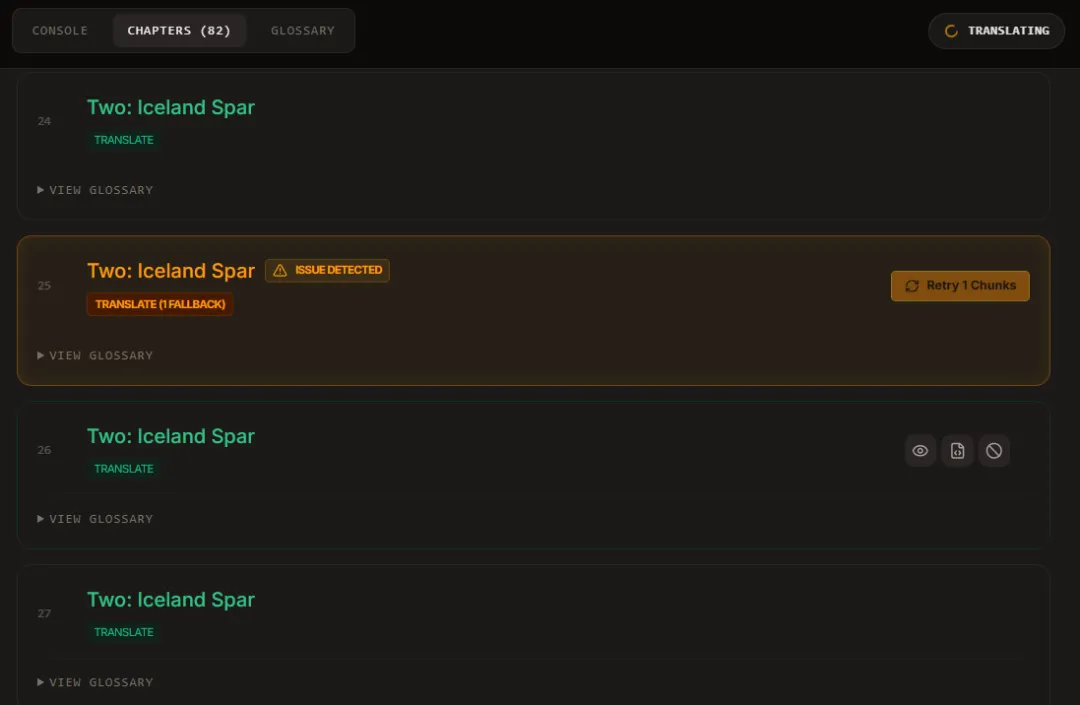
翻译结束后再次查看 CHAPTER 页面。如下图所示,橙色表示有片段翻译不成功,可以连接第三方 API 重试。
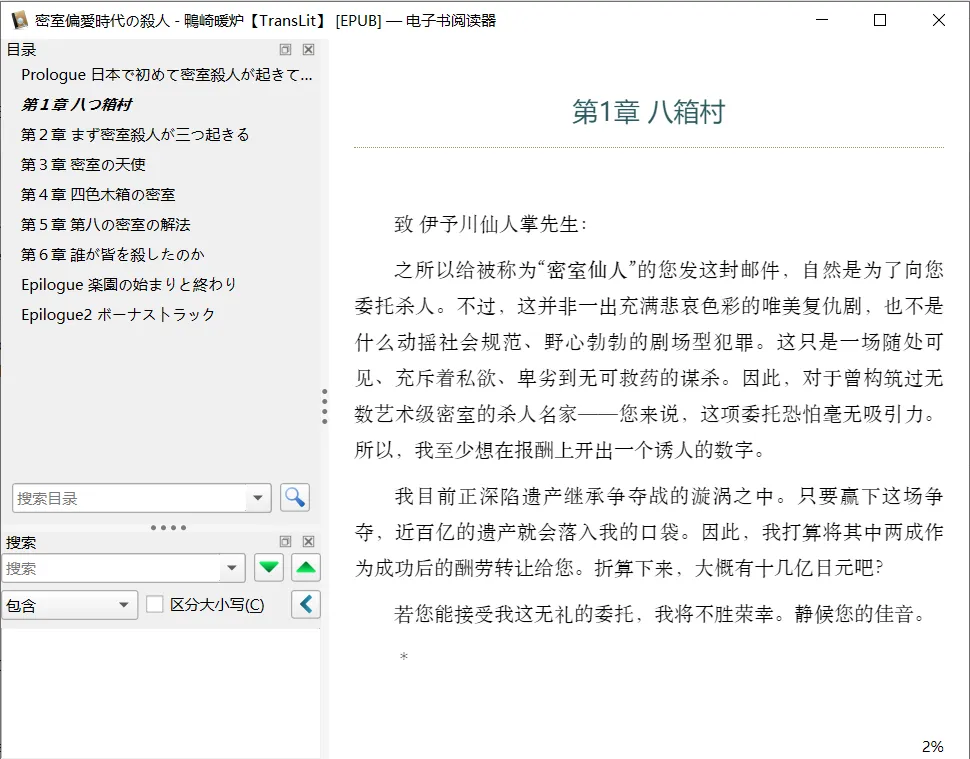
翻译之后 EPUB 效果如下,这部分我一直没有升级过:
参考资料
[1] AiNiee:https://github.com/NEKOparapa/AiNiee [2] LinguaGacha:https://github.com/neavo/LinguaGacha [3] TransLit:https://ai.studio/apps/b184f80d-4fa5-4fce-a431-029da0140dce [4] GitHub - TransLit 2.0:https://github.com/fengyukongzhou/TransLit-2.0
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 电子书推荐丨掌阅精选好书巡游季收官——2025年度“中国好书”:以文字为舟,载时代星河
- 电子书|《我胆小如鼠》 PDF+epub+mobi+azw3 余华笔下的懦弱者如何颠覆生存定义
- 【强推】小说电子书资源分享(5.03)
- 002号电子书截图
- 电子书|《离婚律师唐昭昭:专治各种不服》 PDF+epub+mobi+azw3 金牌律师专治婚姻疑难杂症
- 电子书|《都柏林人》 PDF+epub+mobi+azw3 揭示都柏林瘫痪的精神肖像
- 剑桥硬核书单!20本电子书覆盖数学/物理/生物等核心领域!
- 电子书是效率,纸质书是生活
- 电子书|《简单致富:实现财务自由与富足人生的路线图》 PDF+epub+mobi+azw3 投资指数基金实现财务自由
- 告别书荒!新增2个“神级”电子书资源站,高分好书免费领!
