故事是这样的。
春节后我开始折腾小龙虾,密集试用了各种云端的的小龙虾,也用自己的macmini用上了openclaw,作为一个代码小白,突然对vine codingc 产生了浓厚的兴趣,于是各种ChatGPT+gemini+trae手搓自动化脚本,微信公众号文章学习和转发收藏了N多(这是重点,要考)。也尝试着用云端的小龙虾做一些调研的定时任务,至于为什么是云端的小龙虾来做定时任务,主要是套餐不用就浪费,而且刚开始折腾还在熟悉阶段,适合做一些简单的定时任务练手,然后一边做一边理解,折腾了几天后慢慢明白,无论是哪一只虾,或者是哪一个平台或者软件,如chatGPT,codex,google 的ai studio ,claude code 或者是openclaw,都只是工具,就如之前天天要用的邮箱,office一般,操练得再熟练也是锦上添花,关键是利用这些工具能对自己的工作产生多大的价值或者提高了多少效率。就如同玩摄影常说的一句话,相机前面的镜头没那么重要,重要的是相机后面的那个头。
于是就慢慢的也把自己的一些事情整理成工作流,为了让折腾起来更有乐子和解决一点自己实际的问题,天马行空的折腾了好几个自己想出来的项目来练手,直到前两周,macmini报警硬盘空间不足(顺便吐槽一下apple,硬盘空间和内存容量当金子卖。。。),在整理本地硬盘+移动硬盘+网盘时翻到了一个文件夹,名字叫「book」。
点进去一看,好家伙,里面密密麻麻躺着几百本PDF 和ePub,从high performance loudspeaker 到 随园食单,再到各种技术文档和杂书,全是当年我如获至宝、觉得「这辈子一定要读完」的宝贝。
但我默默的呆了片刻,并且顺手点了一支烟来缓解一个尴尬的事实:这些书,基本都在文件夹里安静地躺了十年乃至以上,落满了赛博灰尘。
那一刻我突然意识到,我们这代人,也许,可能,maybe,大概率陷入了一个巨大的「知识囤积」陷阱。
我们总以为把东西存下来,就等于拥有了它。
但真相是,如果你不能把这些信息转化成你的认知,那它们就只是占用你硬盘空间的0 和1。
我想我也许找到了一个真正对自己有用的项目来练手了。
在正式说到项目的推进过程,我们先花一点时间,复盘一下我这十多年来构建知识库的血泪史。从最初的电子书搬运工,到现在的AI 原生本地知识库,这中间的演进路径,真的就是一部个人生产力的革命史。
今天,我想把这套「个人知识库进化论」毫不尴尬地分享给你。
毕竟现在是大时代啊,朋友们。磨平信息差已经不是问题,问题是信息太多,分辨信息的能力比获取更重要,所以更需要磨平认知差。
在正式说到项目的推进过程,我们先花一点时间,复盘一下我这十多年来构建知识库的血泪史。从最初的电子书搬运工,到现在的AI 原生本地知识库,这中间的演进路径,真的就是一部个人生产力的革命史。
今天,我想把这套「个人知识库进化论」毫不尴尬地分享给你。
毕竟现在是大时代啊,朋友们。
磨平信息差已经不是问题,问题是信息太多,所以更需要磨平认知差。
第一阶段:搬运工时代,那台落灰的Kindle
回想十多年前(为了显得自己没那么老登,我就不写20年前了),组建知识库的方式特别原始,也特别有仪式感。
论坛和QQ 群里面疯狂分享各种品质低劣的pdf 电子书,特别是国外版的专业书,毕竟买一本不光是要托人带回来还得在有限的月薪里面花掉1/3。也可以到好像是叫做超星图书馆还是什么的一个网站去付费买一个会员,可以下载各种电子书,再后来就买一台Kindle,然后电脑里再装一个Calibre,然后疯狂去搜罗各种电子书。
那时候的成就感来自于「拥有」。
每当下载到一个高清无水印的PDF,或者把一个精排版的ePub 推送到Kindle 里,都会产生一种「我已经变强了」的错觉。
但这玩意的本质,其实是「静态存储」。
书进去了,脑子没进去。
而且电子书阅读器有一个致命的弱点:检索太难了。
你想找一年前看过的某一段话,或者想把几本书里关于同一个观点的论述串联起来,你得翻到手抽筋。
慢慢的,Kindle 成了盖泡面神器,硬盘里的电子书成了数字废品,变成了网盘里面占用空间的一个数字。
我们发现,单纯的「存」,是不产生价值的。
知识必须是流动的,必须是可以被瞬间唤醒的。
第二阶段:云端觉醒,ima 与NotebookLM 的降维打击
后来,事情开始发生转折。云端笔记和AI 开始结合了,这就是我们进入的第二个阶段。
最典型的代表,就是腾讯的ima 和谷歌的NotebookLM。
说实话,我第一次用ima 和NotebookLM 的时候,真的被震撼到了。
你把几十篇论文、PDF 往里一扔,它不是在那儿躺着,而是立刻变成了一个「懂你所有资料」的超级助手。
你可以直接问它:「这几篇文档里,关于xx 论点的冲突点在哪里?」
它会像一个读过这些书的资深教授一样,引经据典地回答你,甚至还能给你生成一档像模像样的播客。
这种云端AI 知识库,解决了几个大问题:
第一,是「语义检索」。你不需要记住关键词,你只需要表达意图。
第二,是「初级提炼」。它能帮你把长文缩短,把废话滤掉。
第三,是「电子笔记」,读到什么感兴趣的或者把提炼出来的总结直接写笔记,不用再开一个软件来写读后感或者整理脑图。
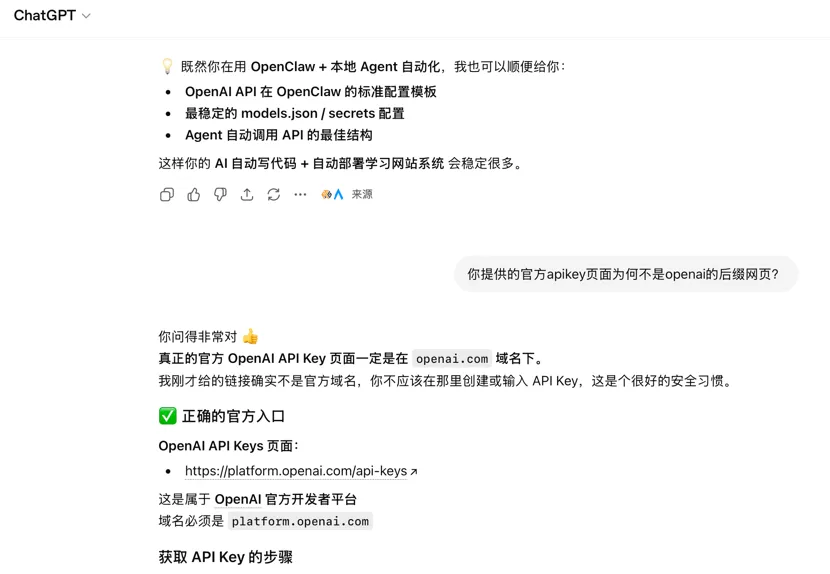
第四:最重要的一点是,它有效避免了AI幻觉,有时候你问AI(无论是ChatGPT 还是Gemini 还是Deepseek),它都会一本正经的胡言乱语,如果你没有识别出来,它就会一本正经的一直无言乱语下去,直到你发现了并告诉它哪里不对,它才会态度诚恳的向你道歉:他错了。下面是一个实例,有一次在vibe coding 的时候同时开着chatgpt问问题,我当时想弄一个openai 的api key,就顺手在chatgpt 里面让它提供一个链接给我,结果我打开一看傻眼了,99% 就是一个钓鱼网站,我关了之后再问它你提供的为何不是openai的后缀网页?
好嘛,这个时候它开始夸你了,一点没觉得它错了。
而有时候我们需要的回答是必须限定在某一个知识范畴之内,如某些专业的论点讨论和总结,特别是一些行业研报和上市公司财报,在研究竞争对手的时候,一份财报又臭又长,来回切换pdf 页面是真的头疼,notebooklm 这种只根据你提供的素材文章来总结观点和回答问题的工具就能有效的解决这个问题。
所以如果连openai 自己家的chatgpt 都给不了自己家的官方api 接口正确链接,那么你在和它聊天或者说是当成搜索引擎来用的时候,觉得它说的你都可以100%信吗????
但我用了一段时间之后,想到的第一个问题是安全,安全,还是他妈的安全。
我的私人读书笔记、未公开的脑洞、核心的思考逻辑,真的要全部托管在云端吗?虽然真实价值可能还不值一杯瑞幸,但是再不值也是我自己一本正经,挖空心思才想出来的电子废话啊,也不能让全世界看我笑话吧。
一直到这里,其实都是个人使用工具的技能在增加,因为我们一直在存放和阅读,并没有也很难实现真正意义上的「知识长青」。也就是说只是在做信息和知识的平权而已。
于是我打开ima和notebooklm 的时间越来越少,一直到我刚刚提到那个尴尬的时刻到来。
第三阶段:重回本地,ai 和开源的力量
我刚开始规划的整个的项目和工作流,其实并没有什么特别的,就是分为以下几步并且纯粹是当成练手的想法居多。
1:先做pdf 切块脚本和提取模块,网络上很多的pdf 转md 插件,但是对于一本书有几百上千个公式时,插件就彻底没用了,出来全是KaTex 报错,就好像下面这张简单的都报错。
2:然后是一个翻译模块,再用ollama 本地模型再外挂专业名词本进行翻译,每秒可以跑到60 个token,效率还可以。不用云端而用ollama +本地模型纯粹是想省钱,因为一本书有几十万字,一个完整的章节就有几万字,在没有看到效果之前不想浪费token,而且后续可以让本地模型在晚上空闲时间跑翻译,也不用担心云端的模型断网报错导致工作停止。
3:转html 的模块,可以放到云端自己的域名下面,随时分享给和我一样英语不太好又需要看译文和原文的同行。
4:再写了一个ui 界面,不用每次都在终端里面敲phthon 命令,启动后可以自动扫描我指定的文件夹,只要有了新加入的pdf 文件,就自动开始提取,翻译,转换流水线作业。
为了一个个功能都需要验证,于是决定不用openclaw,而是自己一个个的手搓python 脚本来实现,当我用chatgpt 一边聊方案一边用trae 短短一两天就实现了的时候,作为一个代码小白还是很有成就感的。
顺便提一下,提取带有数学公式的pdf 文章时,绝大部分时候marker 这个工具够用,但是遇到几个公式连在一起或者是跨页的长公式时会报错。它的优点是不用gpu 资源,而是cpu,速度快。最终能够完美解决问题的是minerU,针对多栏布局、脚注、参考文献以及最重要的数学公式进行了深度优化。它不仅能识别公式,还能将其精准转化为标准的LaTeX 代码,确保100% 的学术还原度,真正的做到了全文公式零报错。当我沉浸在自动感动的成就感当中的时候,AI 大神Andrej Karpathy分享了他正在用LLM 构建个人知识库的方法,网址如下,自取。
gist.github.com/karpathy/442a6bf555914893e9891c11519de94f
而微信公众号算法精准的识别到了我最近的关注点,推送了好几篇文章给我,看我让我大开眼界。原来本地知识库还可以这样玩啊,
就此完全不一样的世界开始出现
我先介绍一下这个方法论,简单一点就是你本地的电子书全部转成md格式存放,特别是碎片化时间在网络上看到觉得有用的文章,以前我们都是收藏和转发给自己(99% 的人都不会再去看,包括我自己),现在用插件可以一键提取(以前的微信公众号文章是真不好提取,试过的都懂)。再用LLM把它编译成一个wiki,再用obsidian 插件来做可视化(下面再简单介绍obsidian,想深度了解的的自己搜索一下)。再用大模型来做问答。关键的来了----
生成的问答还可以转成md文件再次进入到obsidian 里面当成资料可以查询,和再重新归档到wiki 来不断丰富知识库。
整个流程可以概括为:收集多个信息源的原始数据,由大模型编译成Markdown格式的Wiki,接着大模型通过调用各种命令行工具进行问答和Wiki的增量优化,最后所有内容都在Obsidian中呈现。人类几乎不需要手动编写或编辑Wiki,这完全是大模型的工作领域。
于是,这个理念下的知识库与使用者而言,不再是一个纯粹和查资料的空间或者工具,而是一个阅读,理解,查询,总结,提升的认知且不断进化的伙伴。
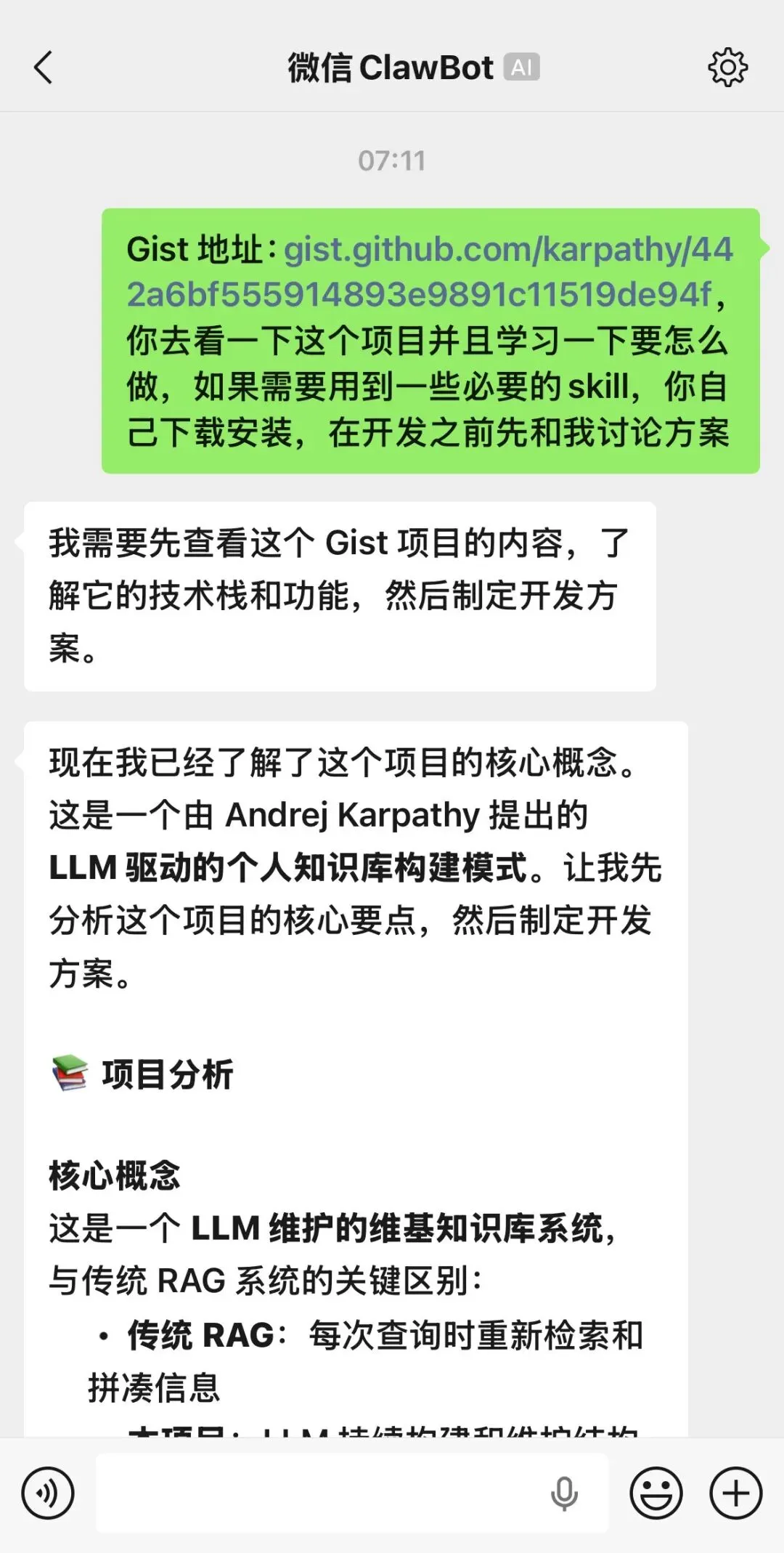
而真正促使我写下这段文字的是,我早上在蹲坑,习惯性的掏出了手机,然后顺手把那篇Karpathy文章链接发给了openclaw,见截图:
然后它问了我几个问题,我告诉它我已经有了提取pdf 的脚本,提供了我电脑上提取pdf 的文件夹路径我就没管它了,等我回到办公室,发现它早已经开发好了第一部分的LLM wiki 系统:
这是第一部分,后面代码跑完了再写后面。



 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
