今天!换了一个ai聊电子书整理这事儿,有了新的思路,感觉这个流程更符合我的情况
图书馆索引法——先给所有书做一个可搜索的“书名目录”,然后再用AI对某本感兴趣的书做深度解析。
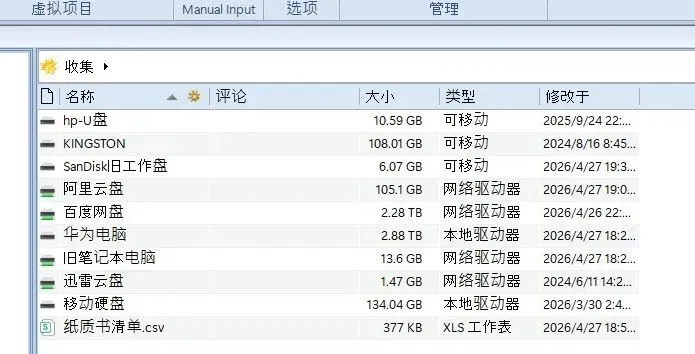
🗂️ 第一步:建立“图书馆总目录”
目的是能跨网盘、跨硬盘,用一个界面搜索所有藏书,不用纠结文件存在哪里。
工具准备:
操作步骤:
把所有散落的移动硬盘、U盘都插上电脑,网盘也保持同步状态。
网盘挂载可以看我之前的内容
电子书整理
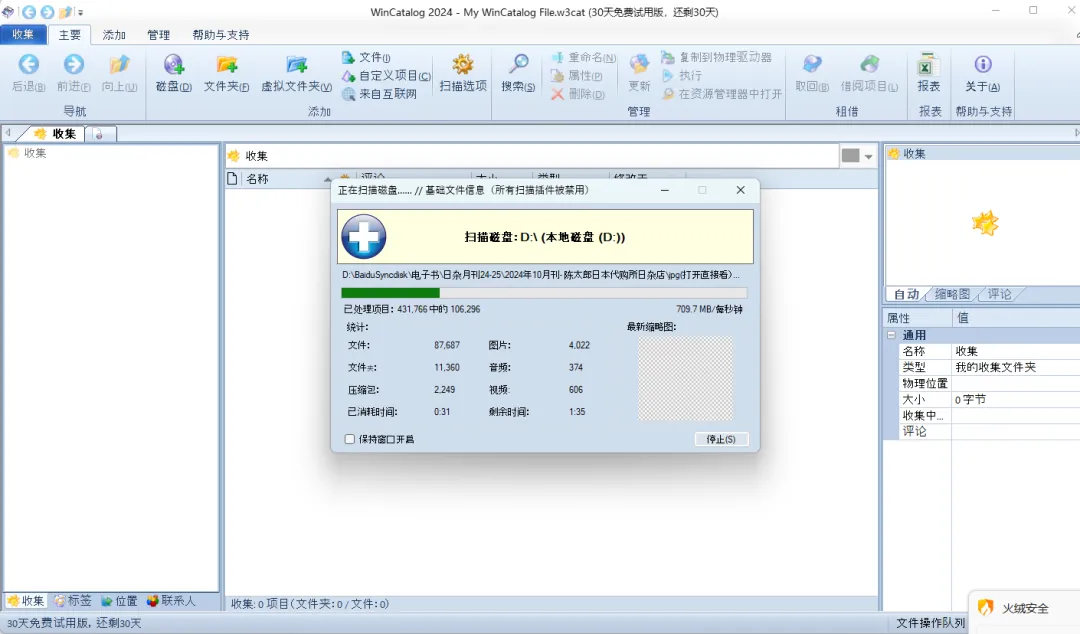
2.打开 WinCatalog,为每个硬盘、每个网盘目录分别创建一个“快照”。
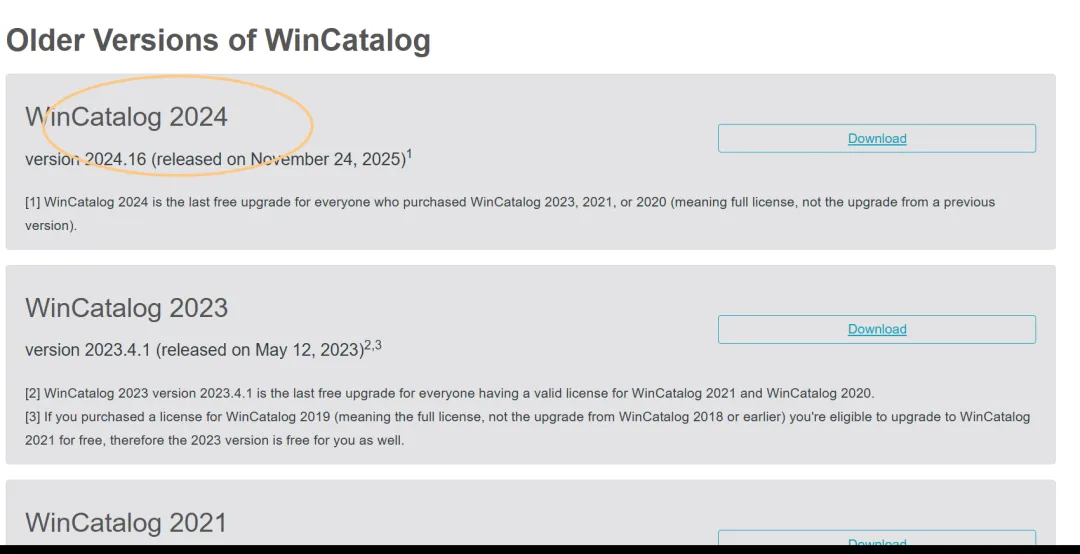
wincatalog有30天免费试用期,ds说够用了,网上也有那种免费版,怕不安全还是用官网的版本了。
但非常搞笑的是2026最新版里没有中文语言包,明明官网是说支持中文的,换成2024版的才有了。
官网首页点download然后拉到页面最底下,有各种旧版本
纸质书我是用微信小程序小书房管理的,可以导出清单
小书房
微信读书的书架用网页版截了屏
至此基本上真是把我能想到的所有存储介质里的文件全扒拉了一遍
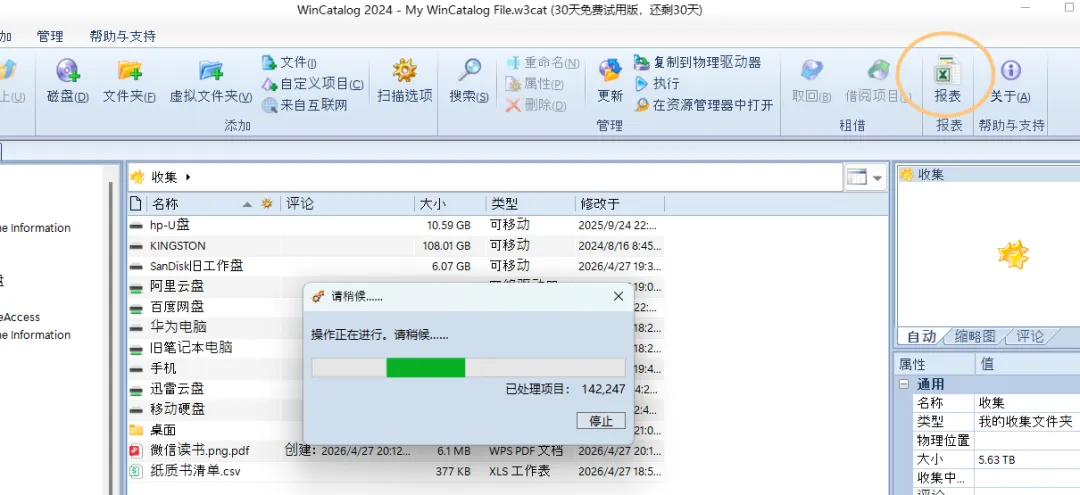
3.所有存储收集完成,此时可以在搜索软件里用.pdf .epub .zip等后缀进行全局搜索。并把搜索结果(所有电子书的全文件路径)导出成一个CSV文件。现在,我们就拥有了一个“图书馆总目录”。这个目录本身就是接下来喂给AI的起点。
🧠 第二步:让AI先“浏览”整个书库,生成推荐摘要
把刚生成的 “总目录” 直接喂给云端AI(用ChatGPT、Kimi、DeepSeek的网页版就行,免费额度足够),配合以下提示词:
“这是我从各个硬盘收集来的所有电子书文件列表。请帮我分析这个书库,指出它主要覆盖了哪些知识领域,并列出每个领域里你认为最经典、最值得优先阅读的10本书。最后,根据这个清单,给我一个为期3个月的阅读建议。”
这样我们可以对自己的藏书有一个宏观认知,获得一个明确的探索起点。
🎯 第三步:先挑20%“种子书”,跑通AI解析流程
从AI的推荐里,或者最近感兴趣想读的书里,只挑出20-30本文字为主的EPUB或文字版PDF,作为“种子书”来跑通AI解析的流程。
扫描版PDF还是用umi-ocr或者mineru:
umi的话前两篇里我也有写
电子书整理
mineru本来我是因为最新版不能直接添加文件夹才去找旧版的,如果每次转换文件数量不多,那直接用官网最新版还是可以的。
📖 第四步:扫描版PDF-“随用随转”
剩下的几百G资料,没必要现在全都处理掉,反正一下子也是看不过来的。
“随用随转”流程举例:
最近太平年正播呢,对“宋朝历史”产生了兴趣。
打开 Everything,搜索 宋朝 历史.pdf。
瞬间找到3本相关的扫描PDF。
发现其中第2本很有意思,于是只拖这一本到Umi-OCR转换,同时把输出的TXT发给AI做解析。
10分钟后,解析结果出来了,决定是否精读。其他两本原封不动,等待下次再考虑要不要读。
这个从宏观索引建立,到少量种子书跑通流程,再到按需解析的完整路径,让我在电子书整理这件事情上有了一点方向,白天跟ds聊到这里的时候就很开心,有种总算弄明白了的感觉,明天多喂几个ai看看生成的阅读方案吧。

 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
